BIORAG:ARAG-LLMFrameworkforBiological Question Reasoning
이 논문은 BIORAG라는 생명과학 분야의 질문-응답 시스템을 제안하며, 최신 연구와 복잡한 생명과학 데이터를 효과적으로 다루기 위한 Retrieval-Augmented Generation (RAG) 프레임워크를 소개합니다. 주요 내용은 다음과 같습니다:
1. 배경 및 문제 정의
- 생명과학 연구는 빠르게 발전하며, 최신 발견과 복잡한 지식 구조를 요구.
- 정확하고 포괄적인 정보 검색 및 응답 생성은 여전히 큰 도전 과제.
2. BIORAG 프레임워크
구조 및 워크플로우:
- 내부 정보 소스:
- NCBI의 PubMed 데이터에서 고품질 초록(2,237만 개)을 필터링하여 사용.
- PubMedBERT를 기반으로 한 Memb 임베딩 모델을 활용하여 검색 성능을 최적화.
- MeSH(Medical Subject Headings)를 사용해 구조적 정보 검색 수행.
- 외부 정보 소스:
- 생물학 데이터 허브:
- Gene, dbSNP, Genome, Protein Database 등 특화된 생물학 데이터베이스 통합.
- 검색 엔진:
- Google, Bing, arXiv 등 다양한 검색 엔진으로 최신 정보 보충.
- 생물학 데이터 허브:
- Self-evaluation 전략:
- 내부 검색 결과의 충분성과 적합성을 평가.
- 부족한 경우 외부 소스를 추가 활용하여 반복 검색 수행.
- 질문-응답 생성:
- Llama3-70B를 언어 모델로 사용하여 최종 답변 생성.
3. 실험 설정
- 최대 검색 결과:
- 생물학 데이터베이스 및 검색 엔진: 각 10개.
- PubMed 데이터베이스: 최대 4개.
- Self-evaluation 반복 횟수:
- 최대 15회 반복하며, 답변이 생성되지 않으면 현재 결과를 반환.
- 평가 지표:
- 정확도(Accuracy), 재현율(Recall)을 사용해 성능 평가.
4. 실험 결과
성능 비교:
- BIORAG는 BioLLMs, GPT-3.5, SciRAG(NewBing)보다 우수한 성능을 보임.
- BioLLMs:
- 도메인 특화 데이터로 파인 튜닝하면 성능이 향상되나, BIORAG가 더 나음.
- GPT-3.5:
- 일반 언어 모델보다 도메인 특화 프레임워크인 BIORAG가 뛰어남.
- SciRAG(NewBing):
- 데이터 크기는 SciRAG보다 작지만, 특화된 데이터와 맞춤형 프롬프트 덕분에 더 좋은 성능.
- BioLLMs:
- GeneGPT:
- GeneTuring 데이터셋에 특화된 모델로, 일반화 능력이 부족하여 다른 작업에서 성능 저조.
5. 결론
- BIORAG는 내부 및 외부 정보 소스를 통합하고 Self-evaluation 메커니즘을 적용하여 정확도, 효율성, 최신성을 확보.
- 생명과학 분야의 복잡한 질문-응답 작업에서 기존 모델(GPT-3.5, SciRAG 등)을 능가하는 성능을 입증.
- 연구자들에게 더 나은 의사결정과 지식 활용을 지원하는 강력한 도구로 자리매김할 가능성을 제시.
Investigating Continual Pretraining in Large Language Models: Insights and Implications
이 논문은 대규모 언어 모델(LLMs)에서 연속 학습(Continual Learning, CL)을 통해 다양한 도메인 간 지식을 효과적으로 통합하면서도 기존 지식을 유지하거나 전이하는 방법을 연구했습니다. 다음은 주요 내용을 정리한 것입니다.
1. 연구 목적 및 배경
- 연속 학습의 목표:
- 모델이 새로운 도메인의 데이터를 학습하면서도 기존 도메인 지식을 유지하고, 이를 기반으로 다른 도메인에 지식을 전이.
- 기존 연구와 달리, 특정 도메인 식별자를 사용하지 않으며, 현실적인 데이터 환경에서 모델의 적응력 및 성능을 평가.
- 연구 기여:
- 도메인 간 연속 학습의 효과를 평가할 새로운 벤치마크 및 지표 제안.
- 도메인 순서, 모델 크기, 데이터 균형 등의 변수들이 연속 학습 성능에 미치는 영향을 실험적으로 분석.
2. 주요 실험 설정
- 모델 및 데이터셋:
- 모델: GPT2 (small, medium, large, xlarge)와 RoBERTa (base, large) 사용.
- 데이터셋: Wiki 및 S2ORC 도메인으로 구성된 M2D2 데이터셋 사용.
- Wiki는 일반 지식 도메인, S2ORC는 세부 학술 도메인을 포함.
- 훈련 순서:
- 유사 순서(semantically ordered): 도메인 간 유사성을 기준으로 학습.
- 랜덤 순서(randomly ordered): 도메인을 무작위로 학습.
- 평가 지표:
- Perplexity: 도메인별 테스트 성능 평가.
- Backward Transfer: 새로운 도메인 학습이 이전 도메인 성능에 미치는 영향.
- Forward Transfer: 이전 도메인 학습이 새로운 도메인 성능에 미치는 영향.
3. 주요 발견
(1) 연속 학습 성능
- 유사 순서 학습:
- 최근 학습 도메인과 개념적으로 유사한 도메인 간에는 효과적인 전이 가능.
- 그러나 도메인이 변경되거나 연관성이 낮을 경우 성능 저하 발생.
- 랜덤 순서 학습:
- Backward 및 Forward Transfer에서 전반적으로 더 나은 성능.
- 장기적으로 더 다양한 도메인 간 지식 축적이 가능.
(2) Forward Transfer
- 도메인 순서와 학습 범위가 forward transfer에 중요한 역할:
- 유사 순서: 도메인 간 유사성이 높은 경우 성능 개선.
- 랜덤 순서: 더 넓은 범위의 도메인에 대한 성능 전이 가능.
(3) Generalization (일반화 능력)
- Wiki 도메인 학습은 일반적으로 일반화 성능에 부정적인 영향을 미침.
- S2ORC 도메인 학습은 특정 작업에서 성능을 개선하지만, 일부 도메인에서는 제한적.
(4) 모델 크기
- 큰 모델(GPT2-large, xlarge)은 작은 모델(GPT2-small)보다 더 나은 성능을 유지.
- 그러나 작은 모델은 연속 학습에서 상대적으로 큰 향상을 보임.
(5) 데이터 크기 균형화
- 도메인 간 데이터 크기를 균형화하는 것은 성능 향상에 효과적이지 않음.
- 모든 데이터를 최대한 활용하는 것이 더 나은 결과를 제공.
(6) Encoder-Decoder 모델 실험
- RoBERTa 모델 결과:
- RoBERTa-large는 RoBERTa-base보다 항상 낮은 성능.
- 망각이 거의 없으며, forward transfer 성능이 뛰어남.
4. 연구의 결론
- 연속 학습의 효과:
- 도메인 학습 순서와 범위가 성능에 중요한 변수.
- 랜덤 순서 학습이 전반적으로 더 나은 backward 및 forward transfer 성능을 제공.
- 모델 설계 및 학습 전략:
- 데이터 크기를 균형화하거나 학습 순서를 변경하는 것보다는 다양한 도메인 데이터 학습과 효율적 모델 설계가 중요.
- 실용적 시사점:
- 연속 학습은 현실적인 도메인 학습 환경에서 언어 모델 성능을 높일 수 있지만, 도메인 순서와 모델 구조가 이를 크게 좌우.
Adaptation Odyssey in LLMs: Why Does Additional Pretraining Sometimes Fail to Improve?
이 논문은 대규모 언어 모델(LLMs)의 추가 훈련과 그로 인한 일반화 및 적응 능력 변화를 연구한 내용입니다. 주된 내용과 연구 결과를 정리하면 다음과 같습니다:
배경
- 전통적인 딥러닝 vs. LLMs
- 과거 딥러닝 모델의 일반화와 적응 능력은 고정된 훈련 및 테스트 데이터 분포를 통해 평가되었습니다.
- LLMs는 전통적 딥러닝과 크게 다르며:
- 매우 높은 매개변수 수를 가지고 있으며,
- 인터넷에서 수집된 레이블이 없는 텍스트 코퍼스로 최소한의 인간 개입으로 훈련됩니다.
- 온라인 방식(Online fashion)으로 훈련됩니다.
- 이러한 차이점으로 인해 딥러닝의 일반화 및 적응에 대한 기존 연구 결과를 LLMs에 직접 적용하기 어렵습니다.
연구 목적
- 이미 사전 훈련된 언어 모델을 추가적으로 훈련(further training)할 때 발생하는 현상을 관찰하고 이해하고자 합니다.
- 특히, 추가 훈련이 같은 도메인의 테스트 데이터에 대한 성능(perplexity)에 미치는 영향을 분석합니다.
주요 결과
- 퍼플렉시티 악화(Degradation in Perplexity):
- 모델을 특정 도메인의 텍스트 데이터로 추가 훈련하면 같은 도메인의 테스트 데이터에 대해 퍼플렉시티가 증가(성능이 저하)되는 현상을 발견했습니다.
- 성능 저하와 데이터 유사성의 관계:
- 추가 훈련 데이터와 원래 사전 훈련 데이터 간의 유사성이 높을수록 퍼플렉시티 악화 정도가 더 크다는 것을 관찰했습니다.
- 토큰 단위 분석(Token-level analysis):
- 퍼플렉시티 악화는 특정 토큰에 집중되어 있으며, 이 토큰들은 해당 도메인에 대해 정보성이 낮은 토큰인 경우가 많았습니다.
의미 및 기대 효과
- 모델을 특정 도메인에 맞게 적응시키는 것이 항상 이점만 있는 것이 아님을 보여줍니다.
- 추가 훈련을 진행할지, 혹은 기존 모델의 기본 역량(foundational capabilities)에 의존할지를 결정하는 데 있어 중요한 통찰을 제공합니다.
Data is all you need: Finetuning LLMs for chip design via an automated design-data augmentation framework
논문 요약
이 논문은 대규모 언어 모델(LLM)을 활용하여 하드웨어 기술 언어(HDL) 코드, 특히 Verilog 코드와 전자설계자동화(EDA) 스크립트를 자동 생성하는 연구를 다루고 있습니다. Verilog 데이터의 부족과 EDA 스크립트 데이터 증강 프레임워크의 부재로 인해 LLM 기반 Verilog 생성 품질 향상이 제한적이었던 문제를 해결하고자, 자동화된 디자인 데이터 증강 프레임워크를 제안합니다. 주요 내용은 다음과 같습니다:
1. 연구 배경
- LLM과 Chip Design: LLM을 활용한 Verilog 및 EDA 코드 생성 가능성을 탐구.
- 문제점:
- Verilog 데이터 부족.
- EDA 스크립트 데이터 준비에 많은 시간 소요.
2. 제안된 데이터 증강 프레임워크
- Verilog 생성
- Verilog 파일을 추상 구문 트리(Abstract Syntax Tree, AST)로 변환.
- AST 노드를 미리 정의된 템플릿을 사용해 자연어와 매핑.
- Verilog 수정(Repair)
- 미리 정의된 규칙에 따라 잘못된 Verilog 파일 생성.
- EDA 도구 피드백과 올바른/잘못된 Verilog 파일을 짝지어 데이터셋 생성.
- EDA 스크립트 생성
- 기존 LLM(GPT-3.5)을 사용해 EDA 스크립트 설명 생성.
3. 모델 학습 및 결과
- Fine-tuning: Llama2-13B 및 Llama2-7B 모델을 데이터 증강 프레임워크로 생성한 데이터셋으로 미세 조정.
- 결과:
- Verilog 생성 정확도:
- 기존 SOTA 모델의 정확도를 58.8% → 70.6%로 향상.
- 제안된 13B 모델(ChipGPT-FT1):
- GPT-3.5 대비 Verilog 생성 및 EDA 스크립트 생성에서 우수한 성능.
- Verilog 생성 정확도:
이 연구는 LLM 기반 Chip Design 분야의 새로운 가능성을 열며, Verilog 및 EDA 데이터 증강 프레임워크의 실질적 유용성을 입증했습니다.
논문 내용 설명
이 논문은 대규모 언어 모델(LLM)을 하드웨어 생성 및 전자설계자동화(EDA) 도구 에이전트로 활용하기 위한 방법론과 데이터를 증강하는 워크플로우를 제안합니다. 특히 Verilog 코드 생성, 오류 검사, 자연어-코드 정렬에 초점을 맞추고 있으며, 데이터 증강을 통해 모델 성능을 크게 향상시켰습니다. 주요 내용을 아래에 정리합니다.
데이터 생성 워크플로우
LLM 훈련 데이터는 다음 세 가지 필드를 포함합니다:
- Instruction: 수행할 작업의 구분(예: 코드 생성 vs 오류 검사).
- Input: 작업의 컨텍스트 또는 프롬프트.
- Output: 작업에 대한 예상 결과.
Verilog 데이터 증강
(1) 두 단계 데이터 증강 프로세스
- 1단계: 많은 양의 정제되지 않은 데이터를 모델에 먼저 노출하여 기초 지식 확장.
- 2단계: 고품질, 정확하게 타겟팅된 데이터를 사용하여 모델 능력을 정제.
(2) Verilog 코드 생성
Verilog 코드는 세 가지 수준으로 분리하여 예측합니다:
- 모듈 수준: 모듈 헤더로 모듈 본문을 생성.
- 문장 수준: 이전 코드의 끝(;) 이후 다음 문장을 예측.
- 토큰 수준: 이전 토큰 시퀀스를 기반으로 다음 토큰 예측.
- 데이터 예시:
{ "instruct": "complete the next [level] of Verilog file.", "input": "[Existing Verilog]", "output": "[Predicted Verilog]" } - 평가 결과:
- Verilog 코드 완성만으로는 정확도가 22.9% → 25.7%로 소폭 향상(Tab. 5).
(3) 자연어와 Verilog 정렬
Verilog 코드의 의미와 자연어를 연결하기 위해 규칙 기반 프로그램 분석을 도입합니다:
- Verilog 코드 → AST 변환: ANTLR4를 사용하여 Verilog 코드를 추상 구문 트리(AST)로 변환.
- 규칙 적용: AST에서 정보를 추출해 자연어로 변환.
- 예시 변환 규칙:
- 모듈 선언:
module x(input a, output reg b);→"The Verilog module with name [x] has one input [a] and one output [b]. The output is reg."
- Always 블록:
- “always @(posedge clk)” →
"The sensitive list in <first> trigger block is <on the positive edge> of <clk>."
- “always @(posedge clk)” →
- 변수 선언:
- “reg [1:0] count;” →
"<Output> signal <count> has <2>-bit width in range <1:0>. It is a <reg> variable."
- “reg [1:0] count;” →
- 모듈 선언:
- 데이터 예시:
{ "instruct": "give me the Verilog module of this description.", "input": "[natural language]", "output": "[Verilog file]" } - 데이터셋 규모:
- 번역 가능한 Verilog 구조체 수(𝑘)에 따라 데이터 크기가 O(𝑘)만큼 선형적으로 증가.
- 성능 결과:
- Verilog 생성 정확도 25.7% → 45.7%로 크게 향상(Tab. 5).
데이터 증강 효과
- 규칙 기반 접근법은 자연어와 Verilog 간의 의미적 차이를 효과적으로 연결.
- GPT-3.5와 유사한 성능을 13B 모델(더 작은 모델)로 달성.
Verilog Repair를 위한 데이터 증강
이 섹션에서는 Verilog 코드 수정(Repair)을 자동화하기 위해 데이터 증강 방법론을 설명하고 있습니다. Verilog 수정 작업은 잘못된 Verilog 프로그램을 자동으로 수정하는 것을 목표로 하며, 이를 위해 현실적인 오류가 포함된 대규모 데이터셋을 생성합니다. 데이터 증강 방법은 크게 두 가지로 나뉩니다.
(1) 목적
- Verilog 코드 작성 시 발생할 수 있는 구문(syntax) 오류를 자동으로 수정하는 작업을 학습하기 위한 데이터 생성.
- 현실적인 오류를 포함한 대규모 데이터셋의 부족 문제를 해결.
(2) 방법
- 정확한 Verilog 코드를 기반으로 규칙 기반 오류 생성:
- Verilog 코드를 ANTLR4로 구문 트리(Abstract Syntax Tree, AST)로 변환.
- 구문 트리의 노드를 마스킹하거나 변형하여 오류를 포함한 데이터 생성.
- 데이터는 다음 형식으로 생성:
{ "instruct": "give me correct Verilog according to the given wrong Verilog.", "input": "[wrong Verilog file]", "output": "[right Verilog file]" }
(3) 오류 유형
다양한 오류를 현실적으로 모방하기 위해 다음 규칙을 사용:
- 키워드, 세미콜론, 연산자 누락: 예) 키워드나 세미콜론을 제거.
- 자료형 오류:
wire→reg또는 반대로 변경. - 비트 폭 오류:
wire나reg정의에서 비트 폭 값을 증가 또는 감소. - 불필요한 단어 추가: 무작위로 의미 없는 단어를 추가.
- 논리 오류:
if문에서 논리 조건을 무작위로 제거.
(4) 데이터셋 확장
- Verilog 코드에 포함된 토큰 수(𝑥)에 따라 2𝑥개의 입력-출력 쌍을 생성.
- 개별 Verilog 모듈당 수정 수를 5개 이하로 제한해 데이터 품질 유지.
2. EDA 도구 피드백을 활용한 Verilog 코드 수정 증강
(1) 목적
- LLM이 생성한 Verilog 코드에서 발생할 수 있는 구문 및 의미 오류를 EDA 도구의 피드백을 활용해 수정.
- EDA 도구가 제공하는 오류 보고를 학습 데이터로 활용.
(2) EDA 도구 피드백 활용 방법
- EDA 도구: Yosys(ASIC 논리 합성 도구)를 사용해 Verilog 구문 오류를 점검.
- 워크플로우:
- 기본 Verilog 수정 증강(3.2.1)에서 생성된 잘못된 Verilog 코드를 Yosys에 입력.
- Yosys가 반환한 오류 보고를 기반으로 잘못된 코드 샘플과 짝지음.
- 데이터 형식:
{ "instruct": "give me correct Verilog according to the given wrong Verilog.", "input": "[yosys info], [wrong Verilog file]", "output": "[right Verilog file]" }
(3) 효과
- EDA 도구의 진단 정보를 활용해 Verilog 코드 수정 작업을 현실적인 도구 제약에 기반.
- 생성된 데이터셋이 실제 도구의 구문 및 논리 오류를 반영.
EDA Tool Script Generation을 위한 데이터 증강
이 섹션에서는 EDA 도구 스크립트 생성, 특히 SiliconCompiler 라이브러리를 사용하여 데이터를 증강하는 방법을 설명합니다. SiliconCompiler는 오픈소스 Python 기반 전자설계자동화(EDA) 프레임워크로, 해당 스크립트를 생성하고 모델 학습을 위한 대규모 데이터셋을 확보하는 데 초점을 맞춥니다.
- SiliconCompiler 라이브러리의 기존 스크립트 샘플이 약 200개로, 대규모 모델의 미세 조정에 충분하지 않음.
- 도메인 지식이 없는 LLM을 활용해 직접 스크립트를 생성할 경우, 구문적으로는 올바르지만 의미적으로는 유효하지 않은 스크립트가 생성될 위험이 있음.
(1) 기존 LLM 활용
- LLM(GPT-3.5 등)의 SiliconCompiler 스크립트 이해 능력을 활용:
- LLM에 약 200개의 유효한 SiliconCompiler 스크립트를 제공.
- LLM이 이 스크립트를 기반으로 자연어 설명을 생성.
- 수식으로 표현: [ \text{GeneralLLM(SiliconCompiler Script)} = \text{Natural Language Description} ]
(2) 데이터 증강 프로세스
- 단계 1: 자연어 설명 생성
- 기존 LLM(GPT-3.5)으로 유효한 SiliconCompiler 스크립트를 입력.
- 스크립트를 설명하는 자연어 텍스트를 출력.
- 단계 2: 스크립트 생성
- LLM이 생성한 자연어 설명을 입력으로 사용하여 다시 SiliconCompiler 스크립트를 생성.
- 데이터셋 형식:
{ "instruct": "give me SiliconCompiler script.", "input": "[LLM generated description]", "output": "[SiliconCompiler script]" }
- 소규모 샘플(200개)만으로도 데이터 증강을 통해 유의미한 성능 향상을 달성.
- 결과 비교:
- 제안된 방법은 GPT-3.5 같은 기존 LLM보다 한 단계 더 높은 수준의 성능을 달성.
- 동일한 작업에 대해 기존 방법이 훨씬 더 많은 학습 데이터를 요구하는 반면, 제안된 방법은 적은 데이터로 효율적인 결과를 보임.
논문의 결론 요약
- LLM 기반 칩 설계는 Verilog 및 EDA 스크립트 생성을 자동화하는 데 높은 가능성을 보여줌.
- 그러나 모델 미세 조정(Fine-tuning)은 훈련 데이터의 부족으로 제약을 받고 있음.
- 이를 해결하기 위해, 설계 데이터 증강 프레임워크를 제안하고 평가:
- Verilog 코드 생성 도메인에서 LLM의 미세 조정을 개선하기 위한 방법론.
- 실험 결과:
- Verilog 생성 정확도가 58.8% → 70.6%로 향상(SOTA 오픈소스 모델보다 우수).
- Verilog 수정(Repair) 및 EDA 스크립트 생성에서 GPT-3.5보다 더 높은 성능을 발휘.
- 제안된 13B 모델이 상대적으로 작은 크기의 모델로도 우수한 성능을 보임.
Improving Domain Adaptation through Extended-Text Reading Comprehension
이 논문은 기존의 AdaptLLM 방법론에서 정규 표현식(Regex)을 사용하여 도메인 특화 코퍼스를 읽기 이해(reading comprehension) 데이터로 변환하는 과정의 한계를 극복하기 위해 새로운 방법론을 제안합니다. 이 섹션에서는 질문-답변(QA) 쌍 생성과 도메인 적응을 효율적으로 개선하는 방식을 설명합니다.
주요 내용 요약:
1. LLM 기반 데이터 전처리:
- 기존 방법론의 한계를 해결하기 위해, 저자들은 ChatGPT와 같은 대형 언어 모델(LLM)을 사용하여 도메인 특화 코퍼스에서 더 풍부하고 유의미한 QA 데이터를 생성합니다.
- QA 생성 과정:
- 각 도메인-specific 문서(예: 의학 논문 초록)를 {DOCUMENT}로 입력합니다.
- ChatGPT에 다음과 같은 프롬프트를 입력하여 QA를 생성:
{DOCUMENT} 위 문단의 내용을 이해하는 데 도움이 되는 몇 가지 질문을 작성하고, 해당 질문에 대한 답을 JSON 형식으로 제공하세요. JSON에는 'question'과 'answer' 두 개의 키만 포함됩니다. - {DOMAIN}은 적용할 도메인(예: 생의학, 금융 등)을 나타냅니다.
- 이를 통해 코퍼스에서 유용한 질문과 답변 쌍을 추출합니다.
2. 비용 문제와 해결책:
- 문제:
- 도메인 특화 코퍼스가 수십억 개의 토큰을 포함할 수 있으므로, API 기반 LLM을 사용한 전처리는 매우 비용이 많이 들고 비효율적입니다.
- 해결책:
- 비용을 줄이기 위해 7B(70억 파라미터) 크기의 LLM을 추가 미세 조정(fine-tuning)하여 QA 쌍을 생성합니다.
- ChatGPT로부터 지식을 디스틸(distillation) 하여 해당 7B 모델을 학습시킵니다.
- 디스틸: 더 큰 모델(ChatGPT)에서 생성된 데이터를 사용해 더 작은 모델(7B 모델)을 학습시켜 성능을 최대한 유지하면서 계산 비용을 줄이는 기술.
3. 추가적인 개선:
- QA 데이터 생성뿐 아니라, 클러스터링을 통해 문맥(context)을 확장하여 모델이 읽기 이해 단계에서 더 풍부한 정보를 사용할 수 있도록 개선합니다.
- 효율적인 파라미터 튜닝(parameter-efficient fine-tuning)을 통해 도메인 적응 과정의 효율성을 극대화합니다.
이 논문에서 제안된 방법 중 문서 유사도를 활용한 문맥 확장(document similarity for context extension)과 관련된 내용을 설명하겠습니다. 이는 질문-답변(QA) 데이터의 품질과 컨텍스트를 개선하기 위한 중요한 단계입니다.
4. 문서 클러스터링을 통한 문맥 확장:
- 개별 문서의 정보를 확장하고 문맥(context)을 풍부하게 만들기 위해 문서 유사도를 활용하여 클러스터를 생성합니다.
- 클러스터는 관련 있는 문서들이 함께 그룹화된 집합으로, 이 과정을 통해 모델이 더 많은 문맥 정보를 활용할 수 있습니다.
5. 클러스터 생성 방법:
- 문서 임베딩:
- 주어진 문서 d를 텍스트 임베딩 모델(M)을 이용해 벡터로 변환하여, 문서 간의 유사도를 계산합니다.
- 클러스터 기준:
- 문서의 길이 합이 사전 정의된 임계값 Lmax를 초과하거나, 클러스터 내 문서 수가 최대값 Dmax에 도달하면 클러스터에 더 이상 문서를 추가하지 않습니다.
- 유사도 기반 추가:
- 문서 di를 클러스터 c에 추가하기 전에, 유사도(similarity)가 0.7 미만인 경우 클러스터링을 멈춥니다.
6. 클러스터 형식화:
- 클러스터 내 문서들을 연결(concatenate)하고, QA 쌍을 무작위로 섞어서 새로운 데이터 형식을 만듭니다.
- 이는 데이터 다양성을 증가시켜 모델이 더 일반화된 학습을 할 수 있도록 돕습니다.
7. 0/1 배낭 알고리즘(knapsack algorithm):
- 생성된 클러스터를 LLM의 최대 컨텍스트 길이에 맞추기 위해 0/1 배낭 알고리즘을 사용합니다.
- 이 알고리즘은 주어진 클러스터 데이터에서 최대한 많은 정보를 선택하되, 총 길이가 모델의 컨텍스트 제한을 초과하지 않도록 조정합니다.
8. 알고리즘 요약:
- 클러스터링 과정:
- 문서를 임베딩하여 유사도를 계산.
- 초기 클러스터를 생성하고, 길이와 문서 수를 확인하며 문서를 추가.
- 유사도가 낮거나 제한 조건을 초과하면 클러스터링을 멈춤.
- 클러스터 형식화:
- 클러스터 내 문서를 연결하고, QA 쌍을 섞어 새 데이터 생성.
- 최종 출력:
- 0/1 배낭 알고리즘으로 최적화된 컨텍스트 데이터를 모델 입력으로 반환.
결론
- 효율성: LoRA와 int8 양자화를 활용한 추가 학습으로 도메인 적응 학습 효율성을 극대화.
- 성능: 다양한 도메인 작업에서 AdaptLLM 및 다른 방법보다 일관되게 우수한 결과를 달성.
- 유효성: 클러스터링을 통한 문맥 확장과 QA 데이터 품질 향상이 도메인 특화 작업과 RAG 작업 모두에서 긍정적인 영향을 미침.
Domain Adaptation of Llama3-70B-Instruct through Continual Pre-Training and Model Merging: A Comprehensive Evaluation
이 논문은 대규모 언어 모델(LLMs)의 도메인 적응(domain adaptation)에 대해 다루고 있습니다. 특히, SEC(미국 증권거래위원회) 데이터와 같은 도메인 특화 데이터를 활용하여 LLM의 성능을 개선하는 방법론을 제안하며, 지속적 사전 훈련(CPT)과 모델 병합(Model Merging) 기법을 결합해 catastrophic forgetting 문제를 해결하는 데 초점을 맞추고 있습니다. 논문의 주요 내용을 정리하면 다음과 같습니다:
배경 및 중요성
- 도메인 적응의 필요성:
- 일반적인 LLM은 다양한 데이터로 훈련되었지만, 특정 도메인에서 요구되는 정확한 정보 제공과 문맥 이해 능력에는 한계가 있음.
- 따라서, 도메인 특화 모델은 업무 생산성 향상과 사용자 경험 개선에 기여할 수 있는 중요한 연구 주제.
- 도메인 적응의 응용 분야:
- 의료, 산업 설계, 금융 데이터 분석 등 특화된 분야에서 LLM의 활용 가능성을 확장.
핵심 연구 주제
1 도메인 적응 (Domain Adaptation)
- 정의: 기존의 사전 훈련된 모델(예: Llama-3-70B)을 특정 도메인 데이터로 추가 훈련해, 해당 분야에 특화된 언어 이해 및 생성 능력을 강화하는 과정.
- 도메인 데이터의 역할:
- SEC 데이터와 같은 구조화된 데이터를 통해 도메인 특화된 문법, 의미론, 감정을 학습.
- 이를 통해 퍼플렉시티 감소, 정확도 향상과 같은 결과를 달성.
2 지속적 사전 훈련 (Continual Pre-Training, CPT)
- CPT의 원리:
- 기존 사전 훈련된 모델(Llama-2-base, Mistral-7B 등)에 새로운 도메인 데이터를 추가로 학습.
- 기존 연구 사례:
- PMC-LLaMA: 의료 데이터를 활용해 ChatGPT와 LLaMA-2를 능가하는 의료 특화 성능을 보임.
- ChipNeMo: 반도체 설계 도메인에서 EDA 스크립트 생성 및 버그 분석 등 3가지 응용 분야에서 성능 개선을 확인.
- Arcee AI의 접근법:
- SEC 데이터를 사용해 지속적 훈련을 수행하여 도메인 특화 모델 성능을 강화.
3 Catastrophic Forgetting
- 문제 정의:
- 도메인 데이터를 추가 학습하는 과정에서 기존 모델이 가지고 있던 일반적인 능력이 손실되는 현상.
- 해결 방법:
- 지속적 사전 훈련과 모델 병합(Model Merging)을 결합하여 문제를 해결.
- 이 방법론은 도메인 특화 성능을 높이는 동시에 일반적 성능 유지에 중점을 둠.
이 논문에서 다루는 모델 병합(Model Merging) 기법은, 여러 사전 훈련된 모델의 능력을 하나의 더 강력하고 다재다능한 체크포인트로 통합하는 방법입니다. 이는 도메인 특화 모델과 범용 대화 모델을 결합하여 두 모델의 강점을 모두 활용하는 데 초점을 맞추고 있습니다.
4. 모델 병합의 개념
- 목적:
- 도메인 특화 지식과 범용 언어 모델의 능력을 균형 있게 결합.
- 기존 모델이 가지고 있는 범용 능력을 유지하면서, 특정 도메인에서 필요한 세부 지식과 성능을 강화.
- 특징:
- 범용 모델의 가중치(frozen weights)를 유지하면서, 새로운 도메인 데이터를 통합하여 성능을 개선.
- 이를 통해 catastrophic forgetting(기존 지식 손실)의 위험을 줄이고, 도메인 적응 과정을 보다 효율적으로 수행.
사용된 기술
- MergeKit(Goddard et al., 2024):
- 다양한 모델 병합 기법을 탐구할 수 있도록 설계된 툴킷.
- Arcee AI는 이를 활용해 모델 병합 실험을 진행.
- 모델 병합 기법:
- Linear (Wortsman et al., 2022):
- 두 모델의 가중치를 선형적으로 조합.
- 단순하면서도 안정적인 방식으로 병합을 수행.
- SLERP (Spherical Linear Interpolation) (Digitous, 2024):
- 구면 선형 보간법을 사용하여 모델 간 가중치를 병합.
- 비선형 공간에서의 조합으로 더 세밀한 조정 가능.
- TIES (Task-Informed Expert Synthesis) (Yadav et al., 2023):
- 특정 작업(task)에 대한 정보를 기반으로 모델 병합을 최적화.
- 도메인 특화 작업에서의 성능을 극대화.
- TIES Merging의 주요 특징
- 여러 작업별 모델을 추가 학습 없이 하나의 다중 작업 모델로 결합합니다.
- 모델 병합 시 발생하는 파라미터 간 간섭 문제를 해결합니다. - 주요 문제 해결
- 중복된 파라미터 값으로 인한 간섭
- 모델 간 파라미터 부호 불일치로 인한 간섭
- TIES Merging의 3단계 프로세스
- TIES는 “TrIm, Elect Sign & Merge”의 약자로, 다음 세 가지 핵심 단계로 구성됩니다:
- Trim (트림)
- 미세 조정 중 작은 변화만 있었던 파라미터를 재설정합니다.
- 각 작업에 필수적인 요소에 모델을 집중시킵니다.
- Elect Sign (부호 선택)
- 파라미터 부호 충돌을 해결합니다.
- 다중 작업 학습에 최적화된 방향으로 파라미터를 조정합니다.
- Merge (병합)
- 최종 합의된 부호와 일치하는 파라미터만 병합합니다.
- 작업별 파라미터를 단일 통합 작업 벡터로 결합합니다.
- DARE (Domain Adaptive Robust Ensemble) (Yu et al., 2024):
- 다양한 도메인 데이터를 통합하여 강건한 성능을 제공.
- 도메인 적응 과정에서 다양한 모델의 성능을 보완.
- Linear (Wortsman et al., 2022):
모델 병합의 효과
- 균형 유지:
- 범용 지식과 도메인 특화 지식의 균형을 유지.
- 단일 모델로 다양한 작업에 적응 가능.
- Catastrophic Forgetting 완화:
- 범용 모델의 가중치를 그대로 유지(frozen)하여 기존의 범용 성능 손실을 방지.
- 적응력 향상:
- 모델 병합 후, 특정 도메인 및 일반적 작업 모두에서 우수한 성능 발휘.
이 부분은 모델의 성능을 평가하기 위해 도메인 특화와 일반적인 작업에서 수행된 다양한 벤치마크 테스트에 대한 내용을 다룹니다. 이를 통해 지속적 사전 훈련(CPT)과 모델 병합(TIES)이 SEC 데이터와 같은 특정 도메인에서 성능을 개선하면서도 모델의 지시 추론 능력(Instruct capabilities)을 유지할 수 있음을 보여줍니다.
평가 대상 모델
다음 세 가지 모델이 서로 비교되었습니다:
- Llama-70B-Instruct:
- Meta에서 공개한 기본 Instruct 모델.
- 원래의 지시 추론(instruction-following) 능력을 보유.
- Llama-70B-CPT:
- Llama-70B-Instruct 모델을 기반으로 지속적 사전 훈련(CPT)을 통해 SEC 데이터를 추가 학습한 모델.
- 20B 토큰 학습 후 저장된 체크포인트 사용.
- Llama-70B-CPT-Merge:
- CPT로 학습된 모델을 TIES 방법으로 원래의 Instruct 모델과 병합한 모델.
- 도메인 특화 지식과 지시 추론 능력을 통합한 모델.
도메인 특화 평가 지표
- Perplexity (혼란도):
- 도메인 특화 데이터에서 모델의 언어 이해 및 적응 능력을 측정.
- Perplexity가 낮을수록 모델의 성능이 뛰어남을 의미.
- CPT 효과:
- 지속적 사전 훈련 후 SEC 데이터에서의 Perplexity가 감소, 즉 모델이 금융 도메인 데이터를 더 잘 이해.
- 모델 병합 효과:
- 병합 후 Perplexity가 약간 증가했으나, 이는 기존 Instruct 모델의 능력(범용 대화 능력)이 다시 도입되었기 때문.
- 최종 모델은 여전히 원래 Instruct 모델보다 Perplexity가 낮아 도메인 적응과 범용 능력 간 균형을 유지.
도메인 특화 작업 테스트
테스트 대상 작업:
- ConvFinQA:
- 금융 데이터와 관련된 추론 능력을 평가.
- TAT-QA:
- 하이브리드 데이터(표+텍스트)를 다루는 작업으로, SEC 데이터와 직접 관련이 없지만 도메인 성능 평가에 유용.
- 금융 텍스트 분류:
- 금융 데이터를 정확히 분류하는 능력.
- 금융 텍스트 요약:
- ROUGE-1 점수를 사용해 금융 텍스트 요약의 품질 평가.
4. 일반 작업 성능
- 병합 후 Instruct 모델의 지시 추론 능력이 회복됨.
- CPT와 병합이 도메인 특화 능력을 유지하면서, 모델의 범용성을 향상시킴.
5. 결론
- CPT 효과: SEC 데이터에서 도메인 특화된 성능이 크게 향상됨.
- 모델 병합 효과: 지시 추론 능력을 회복하며, 도메인 특화와 범용 작업 간 균형을 달성.
- 특히 TAT-QA와 같은 하이브리드 작업에서의 성능 향상은 병합의 유용성을 강조.
- 금융 도메인 및 일반 작업 모두에서 효과적으로 동작하는 강력하고 유연한 모델을 생성.
(FINE-TUNING LARGE LANGUAGE MODELS FOR DOMAIN ADAPTATION) EXPLORATION OF TRAINING STRATEGIES, SCALING, MODEL MERGING AND SYNERGISTIC CAPABILITIES Projection
이 논문은 LLM을 특정 도메인에 적응시키기위한 fine-tuning 전략과 병합 기술을 다룹니다. 주요 내용은 다음과 같습니다.
- Fine-tuning 전략
- Continued Pretrining (CPT), Supervised Fine-Tuning (SFT)
- 선호도 기반 최적화
- Directed Preference Optimization (DPO)
- Odds Ratio Preference Optimization (ORPO)
- 모델 병합 전략
- 두 개 이상의 파인튜닝된 모델을 병합하여 개별 모델의 성능을 뛰어 넘는 새로운 Emergent capabilities 발현
- 병합 과정이 단순 파라미터 합산이 아닌, 비선형적 상호작용을 통해 새로운 기능을 창출할 수 있음을 강조
- 모델 병합에서 부모 모델의 다양성과 훈련 방식이 성능에 중대한 영향을 미침
위 방법을 LLama, Mistral 모델에서 테스트한 결과 모델 병합은 개별 부모 모델의 성능을 뛰어넘는 성과를 보여주었습니다.
Introduction
LLM은 일반적 응용에서 강력한 도구로 자리잡았으며, 현재는 재료공학, 생물학적 재료 설계와 같은 전문적인 도메인으로 그 응용 가능성을 확장하고 있습니다. 하지만 특정 도메인에서는 일반적인 LLM은 지식과 성능이 한계에 부딪히는 경우가 많습니다. 전문 분야에서는 특수한 데이터와 작업 요구 사항에 대한 이해가 필요하며, 이를 위한 추가적인 조정이 필수적입니다. 특정 도메인에 모델을 적응시키는 과정은 단순히 기존 데이터를 추가로 학습시키는 것을 넘어서는 복잡한 과정입니다.
- 훈련 비용: LLM을 처음부터 훈련시키는 것은 비용이 많이 들며, 데이터세트가 공개되지 않은 경우가 많아 제약이 큼
- 데이터 부족: 특정 도메인에서는 학습 데이터의 가용이 제한적
- 기존 지식 유지: 새로운 지식을 학습하면서, 기존에 학습된 범용적인 능력을 유지하는 것이 도전 과제
이전 연구에서는 LoRA 등과 같은 방법을 사용하여 작은 학습 비용으로 새로운 지식을 학습시키려는 시도를 하였습니다. 하지만 이는 다음과 같은 한계가 있습니다.
- 새롭고 복잡한 작업에서의 제한
- LoRA는 기존의 능력을 약간 확장하는 데는 효과적이지만, 완전히 새로운 능력을 부여하기에는 충분하지 않을 수 있습니다.
- 도메인 특화 작업의 새로운 요구사항
- 전문 도메인의 작업은 모델이 기존 훈련과정에서 접하지 못한 다른 유형의 데이터나 문제를 다뤄야할 수 있습니다. 이경우 기존 모델이 지식이 부족하여 LoRA가 추가적인 기능을 학습 시킬 여지가 제한됩니다.
- 학습 되지 않은 기능의 부재
- 기존 모델 지식을 보강하는데 초점이 있으므로, 새로운 개념이나 기능을 학습시키는데는 적합하지 않습니다.
이 논문의 연구 목표는 LLM의 성능을 효율적으로 확장하고, 새로운 능력을 부여하는 데 있습니다.
- CPT: Continued Pretrining
- SFT: Supervised Fine-Tuning
- DPO: Directed Preference Optimization
- ORPO: Odds Ratio Preference Optimization
- SLERP Model Merging
이 연구는 기존 연구와 달리 시스템적이고 체계적인 실험을 통해 다양한 훈련 및 최적화 전략의 효과를 비교합니다. 특히 모델 병합을 통해 비선형적 상호작용으로 새로운 능력을 창출하고 성능을 향상시키는 방법론을 제안합니다.
Related Works
DPO: Direct Preference Optimization
LLM을 인간의 선호도에 맞게 조정하는 방법입니다. 이는 인간의 선호도 데이터를 사용하여 모델을 직접 최적화합니다. RLHF과 같이 별도의 보상 모델이 필요하지 않고 단일 단계로 선호되는 출력과 선호되지 않은 출력 사이의 차이를 최적화합니다.
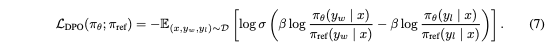
DPO를 적용하기 전의 초기 모델을 참조 모델로 사용하여, 참조 모델로부터의 편차를 페널티로 부과하는 KL 발산 제약을 사용하여, 기존의 정보를 잊어버리지 않도록 조절합니다.
ORPO: Odds Ratio Preference Optimization
이 방법은 선택된응답과 거부된 응답간의 로그 Odds ratio를 활용하여 모델을 미세조정합니다. 거부된 응답에 대해 약간 패널티를 부여하고, 선택된 응답에 대해 강한 적응 신호를 제공하여 모델을 인간선호에 맞게 조정합니다.
여기서 odd ratio는 확률 이론과 통계에서 두 사건간의 상관관계를 나타내는 척도입니다. 즉 어떤 사건이 발생할 확률과 발생하지 않을 확률의 비율입니다.
| odds = p(y | x)/(1-p(y | x)) |
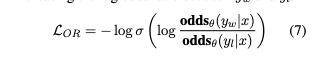
- y_w: chosen response
- y_l: rejected response
Results and Discussion

기존 훈련 파이프라인은 Continued Pretraining을 거친 뒤 Supervised Fine-tuning을 통해 도메인 데이터를 학습합니다. 그리고 선호도 기반 최적화 (DPO, ORPO)를 적용하여 모델의 출력을 개선하는 방식으로 모델을 파인튜닝하였습니다.
대안 파이프라인은 CPT, SFT, DPO, ORPO 등의 최적화를 마친 후, 다른 파인튜닝 모델과 병합하여 성능을 더욱 향상시키는 방법입니다. 병합은 CPT, SFT, 선호도 최적화 이후 어느 단계에서도 적용가능합니다.
모델 병합시 SLERP(Spherical Linear Interpolation)을 활용합니다. 이 기법은 모델 파라미터를 구면 공간에서 부드럽게 Interpolation하는 기법입니다. 구면 공강의 구조를 유지하며 파라미터를 조정함으로써, 단순한 선형 병합보다 더 유의미한 결과를 생성할 수 있습니다. 이를 통해 새로운 기능이 발현될 가능성을 높일 수 있습니다.
선형 병합인 LERP는 단순히 파라미터를 선형적으로 결합하여, 모델 구조를 왜곡하거나, 비효율적인 결과를 초래할 수 있습니다. SLERP는 비선형 경로를 따라 병합하여 모델 파라미터의 상호작용을 최적화하고, 새로운 성능을 끌어낼 수 있습니다.
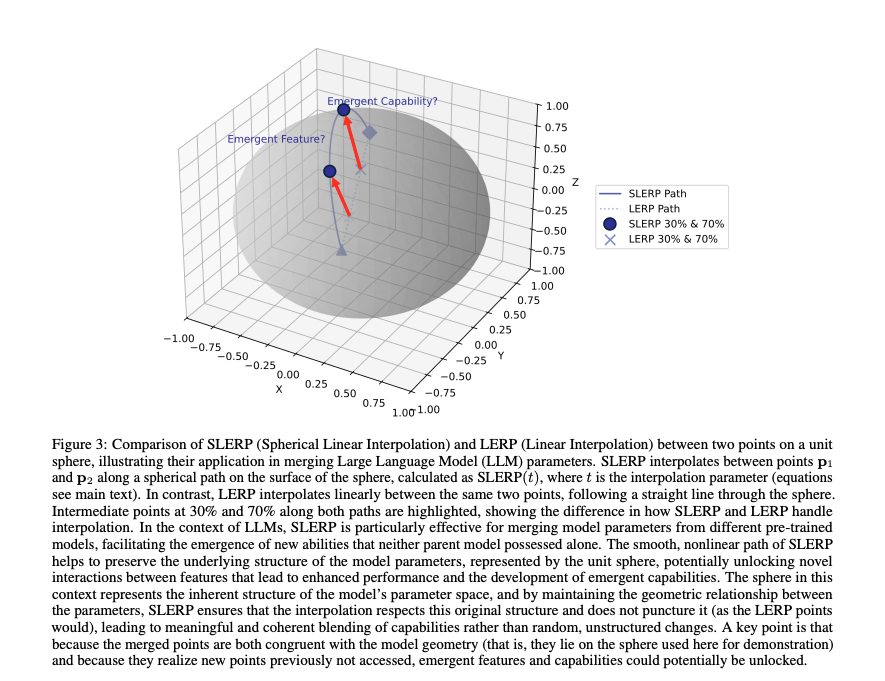
실험은 크게 LLaMA-3.1-8B 모델과 Mistral-7B-v0.3 모델을 각각 Base, Instruct 모델 변형을 사용하였습니다.
- Llama: 훈련 전략은 CPT, CPT-SFT, CPT-SFT-DPO, CPT-SFT-ORPO 등 다양한 방식으로 훈련 및 병합 실험을 수행하였습니다. SLERP를 사용한 병합이 특히 높은 성능을 보였으며 병합하지 않은 모델 중에서는 Instruct-CPT-SFPT-DPO 전략이 가장 우수한 성능을 보였습니다.
- Mistral: SLERP 병합은 이 모델에서도 최고 성능을 기록하였으며, 병합 없이 가장 좋은 성능을 보인 전략은 Base-CPT-SFT 였습니다.
CPT 단계에서 훈련 Epoch 수가 성능에 미치는 영향을 분석하였습니다.
- Instruct 모델: Epoch가 진행될수록 성능이 꾸준히 향상되며, 5Epoch 에서 최고 성능을 달성하였습니다.
- Base 모델: Epoch 초기에는 높은 성능을 보였지만, 추가 훈련에서는 큰 개선 없이 정체하거나 오히려 감소하였습니다.
Instruct 모델이 추가 훈련으로 성능이 크게 개선될 가능성이 높이 도메인 특화 작업에 적합합니다.
Detailed analysis of key factors in model merging
기존의 선형 병합은 단순히 두 모델의 가중치를 선형적으로 결합하여, 종종 높은 손실을 초래하거나, 비선형적인 상호작용 효과를 놓치는 한계가 있었습니다. SLERP는 모델 병합시 구면 선형보간을 사용하여, 비선형 시너지를 활용합니다.

위와 같은 방식으로 모델을 병합하였을때, 더 부드럽고 일반화 가능한 파라미터 조합을 생성할 수 있습니다. SLERP 병합의 성능은 실제 성능(Pmerged)과 예상 성능(E(P1, P2)=(P1+P2)/2) 간의 차이로 분석하였습니다. SLERP 병합 모델의 성능은 예상 성능을 초과했으며, 이는 비선형 시너지 효과에 기인하였습니다. 특히, Llama 모델에서는 Instruct 모델 기반 병합이, Mistral 모델에서는 Base 모델 기반 병합이 최상의 성능을 나타내었습니다.
SLERP는 서로 다른 훈련 이력을 가진 모델 간의 다양성을 활용해 앙상블 효과를 극대화 할 수 있습니다.
Conclusion
- CPT, SFT 는 모든 모델에서 기본적인 성능 향상을 제공하였습니다
- DPO, ORPO는 Llama, Mistral과 같은 대규모 모델에서 성능 개선에 중요한 역할을 하며, 도메인 지식의 정밀도와 모델의 응답 스타일을 개선할 수 있습니다.
- SLERP 병합 기법은 개별 모델의 강점을 보전하면서 새로운 기능을 활성화할 수 있습니다. 그러나 작은 LM에서는 오히려 성능 저하를 보였습니다.
- 데이터 크기의 증가가 항상 성능 향상으로는 이어지지 않았습니다. 품질이 낮은 데이터는 모델 성능 저하를 초래하기 때문에 데이터 품질 개선이 가장 중요함을 발견하였습니다.
MergeKit을 사용하여 모델을 머지하는데 사용하였습니다.